
An Introduction to Ceph
Published:
0x01 Ceph简介
Ceph 是一个分布式存储系统,旨在提供可扩展、可靠且容错的存储解决方案。它支持块存储(RBD)、对象存储(RGW)和文件系统存储(CephFS)。Ceph 是开源的,可以在普通硬件上运行,适合企业级存储需求,且无需硬件 RAID 控制器。
0x02 Ceph的优势
- 通过 CLI 和 GUI 实现简单的设置和管理
- 支持 薄分配(Thin provisioning),提高存储效率
- 提供 快照(snapshot) 支持,方便数据保护
- 具有 自我修复(Self healing) 功能,能自动修复故障
- 可扩展性强,支持从TB 到 PB 级别的存储
- 可以设置具有不同性能和冗余特性的 存储池(Pool)。
- 数据通过 复制 实现容错
- 可以在 普通硬件 上运行,无需昂贵的硬件 RAID 控制器
- 完全 开源,拥有强大的社区支持
0x03 Ceph的核心进程
- Ceph Monitor(ceph-mon):维护集群状态的映射,包括监视器映射、管理器映射、OSD 映射等。它还负责管理守护进程和客户端之间的身份验证。
- Ceph Manager(ceph-mgr):跟踪集群的运行时指标,如存储利用率、性能数据和系统负载,提供 Ceph Dashboard 和 REST API。
- Ceph OSD(ceph-osd):Object Storage Daemon负责存储数据、数据复制、恢复、重新平衡等操作。为了冗余,通常至少需要三个 OSD。
- Ceph Metadata Server (ceph-mds):仅用于 Ceph 文件系统 (CephFS),它负责存储文件系统的元数据,允许执行 POSIX 文件操作。
0x04 Ceph集群部署流程
- 监视器 (Monitors):至少需要三个监视器来确保冗余和高可用性,监视器负责维护集群的状态映射和身份验证。
- 管理器 (Managers):至少需要两个管理器来确保高可用性,它们监控集群的性能指标,并通过 Dashboard 提供集群状态信息。
- OSD:通常需要三个 OSD 来确保数据冗余和高可用性。OSD 负责存储数据并执行数据复制和恢复。
- 元数据服务器 (MDS):仅在使用 Ceph 文件系统时需要,CephFS 的操作依赖于 MDS,而 RBD 和 RGW 则不需要。
0x05 Ceph架构
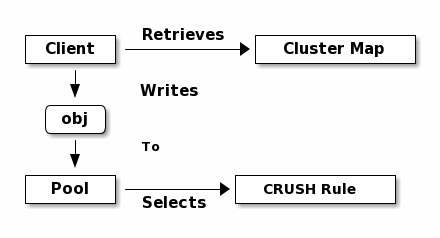
存储池:Ceph 使用存储池(Storage Pools)的概念,逻辑上对存储对象进行分区。每个池由大小、复制因子和 CRUSH 规则定义,这些规则决定了数据的存储方式。
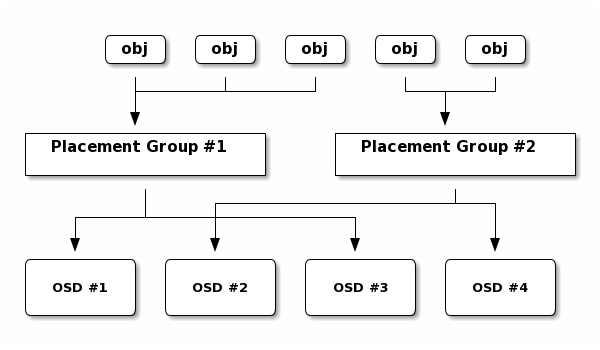
Placement Groups (PGs):数据通过 CRUSH 算法映射到存储池中的 Placement Groups(PGs)。这些 PGs 决定了数据如何分布在集群中的不同 OSD 上。
CRUSH算法:CRUSH(Controlled Replication Under Scalable Hashing)用于将对象映射到 PG,并将 PG 分配给 OSD。CRUSH 算法确保了数据存储的高效性,同时在集群扩展或收缩时实现动态平衡。
0x06 Peering 和 Rebalancing
- Peering:每个 PG 至少需要存储在两个 OSD 上。每个 Acting Set 中的第一个 OSD 被称为 Primary OSD,负责协调其他 OSD 之间的数据同步。
- Rebalancing:当新 OSD 加入时,Ceph 会重新平衡数据,以确保集群的效率和容错能力。
0x07 数据一致性
Scrubbing:Ceph 定期对 PG 中的数据进行检查(scrubbing),以确保数据的一致性。轻度 Scrubbing 检查元数据,而深度 Scrubbing 则能发现并修复磁盘上的坏扇区。
0x08 Conclusion
Ceph 的架构为现代存储需求提供了强大的可扩展性和容错性。通过灵活的存储池和 CRUSH 算法,Ceph 能够高效地分布和存储数据。此外,其自我修复功能和高可用性特性使得 Ceph 成为分布式存储解决方案中的佼佼者。