
计算机网络基础和高性能网络优化
Published:
0x01 计算机网络基础
1. TCP 三次握手与四次挥手
TCP 数据包头部共 20 字节,结构参考下图:
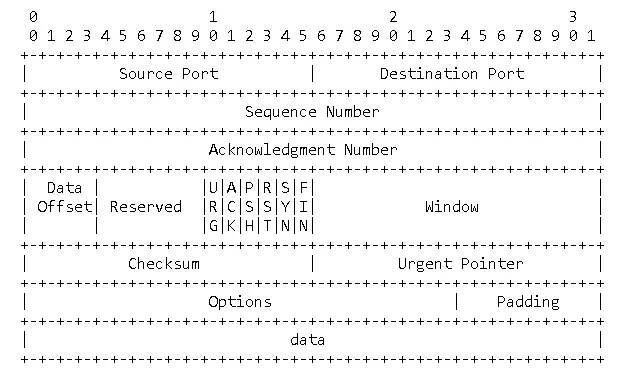
- 0-4 字节:SrcIP / DstIP
- 5-8 字节:Sequence Number
- 9-12 字节:Acknowledge Number
- 13-16 字节:
- 13-14 字节:4 offset + 6 Reserved Data + 6 Signal
- 15-16 字节:Window 大小
- 17-20 字节:
- 17-18 字节:校验和
- 19-20 字节:紧急指针
13-14 byte 的最后 6 bit 为信号标志位,其中就包括 SYN、ACK、FIN 标志位。
三次握手流程
构建 TCP 连接时,三次握手顺序如下,Client 和 Server 都会出一个随机的 Sequence Number,ACK 中返回 seq+1 作为 ACK 编码。
sequenceDiagram
Client-)Server: SYN
Server-)Client: SYN+ACK
Client-)Server: ACK
Why Not:为什么两次无法结束连接
假如将 TCP 三次握手流程改为两次。 Client 端不需要确认 Server 端第二次握手发送的 SYN 包,直接传输数据。
BAD CASE
假设某个 Client 发送的第一个连接请求 SYN-1 因网络延迟而滞留,Client 因未接到 SYN-1-ACK,选择重发,发送了第二个请求 SYN-2 并成功建立了连接,并在数据传输完毕后释放 FIN-2 构造的连接。
此时,延迟的 SYN-1 才到达 Server 端,Server 端将会正常构造连接,而 Client 无法拒绝错误回应,将会被动产生新连接。
四次挥手流程
因为 TCP 是全双工模式连接,所以双方结束连接时,需各自释放连接。
四次挥手过程如下:
sequenceDiagram
Client->>Server: FIN
activate Client
participant Client
Note left of Client: FIN-WAIT-1
Server->>Client: ACK
deactivate Client
participant Client
Note left of Client: FIN-WAIT-2
Server->>Client: FIN
activate Server
participant Server
Note right of Server: LAST-ACK
Client->>Server: ACK
deactivate Server
Note left of Client: TIME-WAIT(2MSL)
Note right of Server: CLOSE
Note left of Client: CLOSE
Why Not:为什么三次无法结束连接
假如将 TCP 四次挥手流程改为三次。 Server 端不等待 Client 端回应第三次挥手请求,直接关闭套接字。
BAD CASE
第四次挥手时,客户端发送给服务端的 ACK 有可能丢失,如果服务端因为某些原因而没有收到 ACK 的话,服务端就会重发 FIN。
如果客户端在 2x MSL 内收到了 FIN,就会重新发送 ACK 并再次等待 2x MSL,防止 Server 没有收到 ACK 而不断重发 FIN…
2. TCP 和 UDP 特点和适用场景
| 协议 | 是否连接 | 是否可靠 | 适用场景 |
|---|---|---|---|
| TCP | 有连接(三次握手) | 可靠、有序、支持重传、拥塞控制 | Web、文件传输 |
| UDP | 无连接 | 不可靠、不支持重传 | 视频、语音、DNS、DHCP |
3. 什么是 MTU, MSS, Window Scaling, Nagle算法
- MTU(最大传输单元):物理网中传输的最大单元,包含协议头部及数据,以太网一般为 1500 bytes。
- MSS(最大报文段):TCP 数据报大小,约为 MTU - 40,即给协议头部留 40 bytes。
- Window Scaling:TCP 窗口调整,支持高带宽延迟网络。
- Nagle 算法:合并小包发送,降低发包频率,减少对系统内核造成的载荷花,但会造成更高的平均延迟。
4. 简述 DNS 原理,递归 vs 迭代查询
- 递归查询
- 客户端 → 本地 DNS
- 请求流程:客户端只发 一次请求,要求对方给出最终结果。由 本地域名服务器 (Local DNS) 一口气查到最终 IP 并返回。
- 返回结果:查询成功或查询失败。
- 迭代查询:
- 客户端 → 本地DNS/向根、客户端 → TLD、客户端 → 权威DNS
- 请求流程:客户端发出 多次请求,对方如果没有授权回答,它就会返回一个能解答这个查询的其它名称服务器列表。客户端会再向返回的列表中发出请求,直到找到最终负责所查域名的名称服务器,从它得到最终结果。
- 返回结果:最佳的查询点 或 主机地址。
sequenceDiagram
autonumber
participant Client as 客户端
participant LDNS as 本地DNS解析器
participant Root as 根DNS服务器
participant TLD as 顶级域DNS(.com / .cn)
participant Auth as 权威DNS服务器
%% 递归查询路径
rect rgb(240,240,255)
Note over Client,LDNS: 🌀 递归查询(本地DNS替客户端完成所有查询)
Client->>LDNS: 请求 www.example.com 的 IP(递归查询)
LDNS->>Root: 询问根服务器(.com 在哪?)
Root-->>LDNS: 返回 .com 顶级域的地址
LDNS->>TLD: 询问 .com 域(example.com 在哪?)
TLD-->>LDNS: 返回 example.com 的权威DNS地址
LDNS->>Auth: 询问 example.com 权威DNS
Auth-->>LDNS: 返回 www.example.com 的 IP
LDNS-->>Client: 返回最终 IP 地址
end
%% 迭代查询路径
rect rgb(255,250,230)
Note over Client,Auth: 🔁 迭代查询(DNS服务器仅返回下一跳)
Client->>Root: 直接询问根DNS(www.example.com)
Root-->>Client: 告诉你 .com 顶级域DNS在哪
Client->>TLD: 继续询问 .com DNS
TLD-->>Client: 告诉你 example.com 权威DNS在哪
Client->>Auth: 最后询问权威DNS
Auth-->>Client: 返回 www.example.com 的 IP
end
5. 底层协议:什么是 ARP、DHCP 协议?
- ARP:IP → MAC 映射,二层通信。
- DHCP:动态分配IP地址。
6. 子网管理:什么是 NAT, VLAN, 子网划分功能?
- NAT:负责私网 → 公网地址转换。
- VLAN:逻辑隔离二层广播域。
- 子网划分:CIDR 记法(如 192.168.1.0/24)控制子网主机数与网络规模。
0x02 网络性能与调优
7. Linux 下如何查看网络连接和延迟
ss -tuna/netstat -anp:查看TCP/UDP连接ping:ICMP往返延迟(RTT)traceroute:每一跳延迟iperf3:TCP/UDP 吞吐测试tcpdump:抓包分析(过滤如tcp port 80)
8. 如何排查高 RTT 成因、丢包现象,以及网络拥塞情况?
ping看波动 & 丢包traceroute定位异常出现在哪跳连接iperf确认对端吞吐是否正常tcpdump确认 TCP 数据包中参数情况,着重看重传次数、窗口大小
指标关注:
- RTT 大 → 拥塞或链路延迟
- 丢包高 → 链路质量差 or buffer 溢出
- 窗口小 → 滞后于 BDP,需 window scaling
9. 简述 TCP 拥塞控制四阶段和内容
- 慢启动(Slow Start):初期指数增长 cwnd,收到一个ack增加一个新窗口。初始拥塞窗口(cwnd)一般为 1~10 个 MSS,每收到一个 ACK,窗口加倍(指数增长),快速探测带宽,但风险高。
- 拥塞避免:线性增长 cwnd。当 cwnd ≥ ssthresh(慢启动阈值)时,进入拥塞避免。每 RTT 增长线性(每轮 +1 MSS),稳健但增长慢。
- 快重传:收到 3 个重复ACK,立即重传。不等超时,若收到接收方 3 个重复 ACK(说明某个包丢了)。立即重发丢失的数据包。
- 快恢复:减半 cwnd,进入拥塞避免而非重头来。快重传后,说明网络可用,但有拥塞。避免 cwnd 退回 1,减少性能损失。调整策略可以用伪代码表述:
- ssthresh = cwnd / 2
- cwnd = ssthresh(或 ssthresh + 3)
- 进入拥塞避免阶段而不是重回慢启动
0x03 高性能网络优化
10. 什么是 busy-polling 和 DPDK
传统网络模型及限制
传统操作系统中,一个数据包的发送了流程可以参考下图:
graph TD
subgraph UserSpace["用户态 (User Space)"]
A["应用程序 (Application)"]
B["Socket API"]
end;
subgraph KernelSpace["内核态 (Kernel Space)"]
C["TCP/UDP 协议栈"]
D["IP Layer"]
E["MAC/以太网 Layer"]
F["NIC Driver"]
end
subgraph HW["NIC Hardware"]
G["硬件队列 (TX/RX Queues)"]
H["物理介质 (Wire)"]
end
A --> B --> C --> D --> E --> F --> G --> H
H --> G --> F --> E --> D --> C --> B --> A
可以看到,一个数据包从用户空间到物理网卡至少要经过两次拷贝:
- 从 User Space 到 Kernel Space
- 从 Kernel Space 到 网卡缓冲区 NIC Hardware
此外,每次 Kernel Space 将数据拷贝到 硬件缓冲 都会引发硬件中断,当大量数据包拥堵时,反复中断引发的上下文拷贝,将会产生大量的冗余消耗
优化网络数据包拷贝路径
graph LR
%% 从左到右的数据流
subgraph Hardware["网卡硬件"]
G["物理介质"]
F["硬件队列"]
end
subgraph Kernel["内核态"]
E["UIO/VFIO"]
end
subgraph UserSpace["用户态"]
C["PMD驱动"]
D["内存管理"]
B["DPDK库"]
A["应用程序"]
end
%% 数据流向
G --> F --> C --> D --> B --> A
E -->|映射| C
E -->|DMA| F
C --> B --> A
数据平面优化技术——DPDK
DPDK(Data Plane Development Kit)是一个开源工具包,提供了一组数据平面库和网络接口控制器轮询模式驱动程序。
可以将 TCP 数据包的处理,从操作系统内核中转移到用户空间中的进程里完成。
DPDK 特点就是:
- 用户态绕过内核协议栈直接访问 NIC Buffer
- 零拷贝 + 多核并发 + 高吞吐
- 适用于高频交易、SDN
优化内核中断机制
busy-polling:CPU 使用 polling 而非 硬件中断 来接收数据包,可以大幅降低低延迟,具体可用内核的 SO_BUSY_POLL参数。
11. 数据包的延迟会出现在哪些环节?
sequenceDiagram
autonumber
participant UA as 用户应用(User Space)
participant K as 系统内核(Kernel)
participant NIC as 驱动 / 网卡(Driver & NIC)
participant L as 物理链路(光纤/铜缆)
participant SR as 交换/路由设备(中间节点,若多跳可理解为多台)
participant RNIC as 远端网卡
participant RK as 远端内核
participant RA as 远端应用
UA->>K: send()/write() 等系统调用
Note over UA,K: [A] 系统层级延迟
K->>K: TCP/IP 协议栈处理
Note right of K: [B] 内核层级延迟
K->>NIC: 报文下发到驱动/NIC
Note over K,NIC: [C] Drive/NIC 延迟
NIC->>L: Byte上线
L->>SR: 入交换/路由设备
Note over NIC,SR: [D1] 物理传播延迟
SR->>SR: 设备处理/转发
Note right of SR: [D2] 交换/路由转发
SR-->>SR: 排队等待(突发/拥塞时)
Note right of SR: [D3] 排队延迟(Bufferbloat)
SR->>L: 出口端口发出
Note right of L: [D1] 继续传播(若多跳则重复 D1/D2/D3)
L->>RNIC: 到达远端网卡
RNIC->>RK: DMA 上送/中断
Note over RNIC,RK: [C] 对端 Drive/NIC 延迟
RK->>RK: 远端 TCP/IP 协议栈处理
Note right of RK: [B] 对端内核协议栈延迟
RK->>RA: 递交到远端应用
Note over RK,RA: [A] 对端系统层级延迟
- [A] 系统层级延迟:从 User Space 到 Kernal Space 调用延迟。
- [B] 内核层级延迟:内核协议栈,如 TCP/IP,协议的处理延迟。
- [C] Drive/NIC 层级延迟:硬件驱动层 到 网卡(NIC)造成的延迟。
- [D] 物理层级传输延迟:
- [D1] 光纤延迟:约 5 μs/km。
- [D2] 交换/路由器处理延迟。
- [D3] 数据包排队延迟Bufferbloat。
12. 可以采用哪些方案优化延迟?
上面提到的延迟来源,每个阶段都有优化方案。
[A] 系统层级延迟优化
- 使用内核旁路 Kernel Bypass 方案绕过 Kernal Space,使用 DPDK 编写发包模块。
- 优化线程的 CPU Affinity ,将关键的进程、线程,物理中断(IRQ),绑定到特定的 CPU Core 上,避免操作系统调度器将系统任务在核心间迁移。从而保证缓存热度、减少上下文切换。
sched_setaffinity系统调用来设置线程的CPU亲和性绑定 CPU core。# 在 GRUB 配置中将指定 CPU 隔离:isolcpus=1,2,3 # 将 my_program 启动,并将其绑定到核心 2 和 3 上 taskset -c 2,3 ./my_program # 对于一个已经运行的进程 PID=12345,将其绑定到核心 1 taskset -pc 1 12345 # 将中断号90绑定到CPU核心2 echo 2 > /proc/irq/90/smp_affinity
[B] 内核/协议层级延迟优化
- 关闭 TCP 协议中 Nagle 配置
- 使用
SO_RCVBUF/SO_SNDBUF调整 socket 缓冲区// 小缓冲区策略 - 减少数据在内核中的停留时间 set_socket_buffers(sockfd, 64 * 1024, 32 * 1024); // 64KB接收,32KB发送 // 大缓冲区策略 - 提高批量传输效率 set_socket_buffers(sockfd, 4 * 1024 * 1024, 2 * 1024 * 1024); // 4MB接收,2MB发送
[C] Drive/NIC 层级延迟优化
- DPDK 内核旁路模式,User Space 直接从 NIC Buffer 的映射中读取数据。
- 轮询策略优化:
epoll:使用 epoll 取代 select 和poll 模式,提升内核态处理中断的效率。busypoll:使用busy_poll套接字接口读取数据,牺牲 CPU 性能,换取最快读取时间。
- 缓存优化:
- 使用巨页(Huge Pages)提高内存访问效率,降低快表(TLB)缺失的概率。